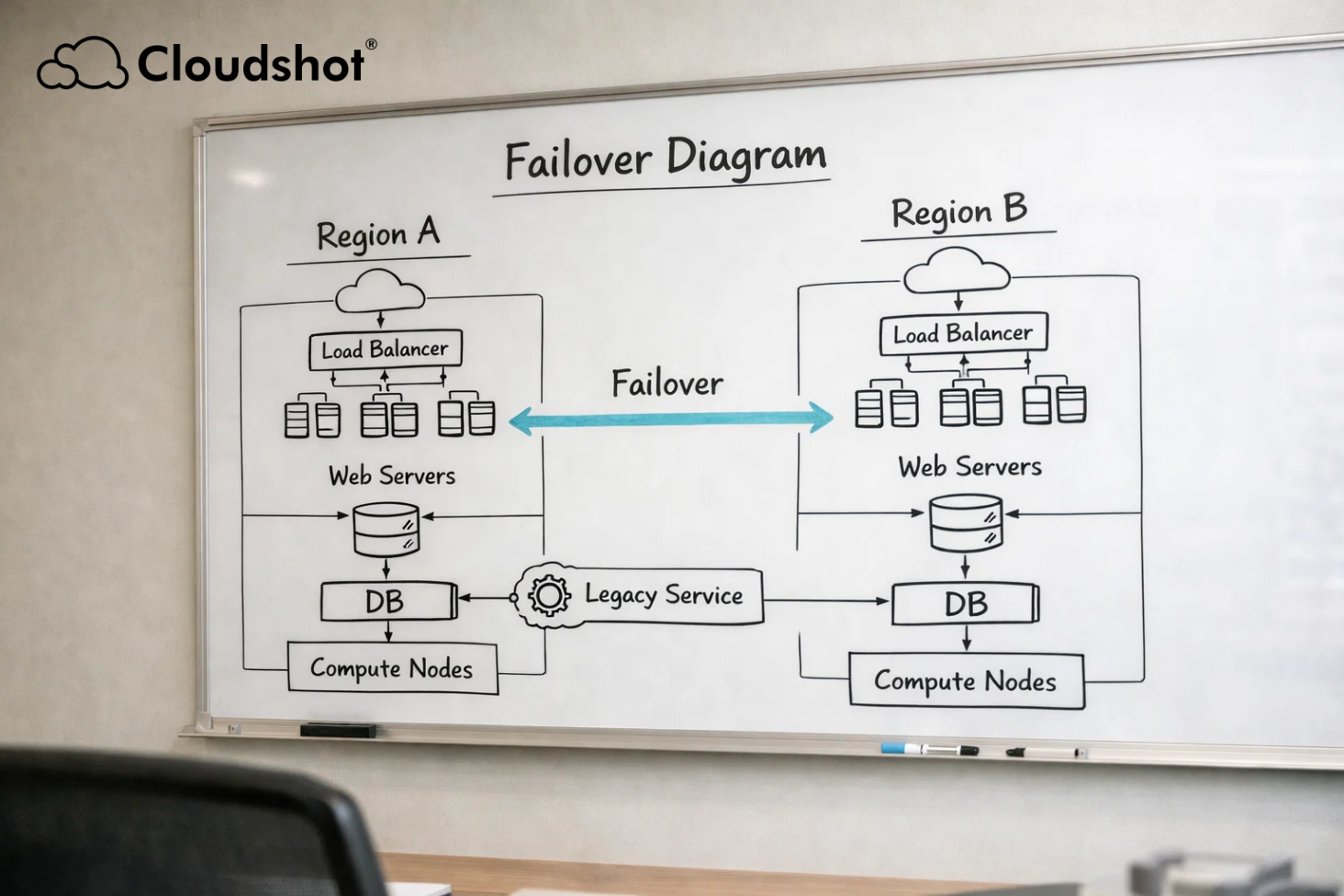
Multi-region architecture is widely considered a cornerstone of cloud resilience.
When systems span multiple regions, teams believe they are protected against regional outages. If one region fails, traffic shifts to another. Applications continue operating.
The strategy is sound.
But the assumption that failover will behave exactly as expected is often fragile.
The Architecture Diagram vs Reality
Most failover designs begin with a clear architectural intention.
A primary region handles production traffic.
A secondary region stands ready as backup.
Data is replicated. Infrastructure templates are reused. Deployment pipelines maintain consistency.
On the diagram, both regions appear identical.
But real cloud environments change constantly.
New services are deployed.
Dependencies evolve.
Configuration adjustments accumulate.
Over time, the primary region becomes the environment teams interact with most frequently.
The secondary region becomes quieter.
And quiet environments tend to drift.
Where Failover Assumptions Break
Cross-region failover failures rarely originate from a single misconfiguration.
They arise from subtle differences that accumulate.
A database replica lags behind schema updates.
An IAM policy differs between regions.
A service dependency exists only in one region.
Autoscaling rules behave differently under heavier traffic.
Individually, these discrepancies seem minor.
Collectively, they undermine failover readiness.
When a real outage occurs and traffic shifts suddenly, the secondary region experiences conditions it was never fully tested under.
The system reveals assumptions that no longer hold true.
The Illusion of Symmetry
Teams often assume that if infrastructure templates are identical, environments remain identical.
But templates only define starting conditions.
After deployment, environments evolve through:
Configuration adjustments
Service integrations
Security updates
Operational workarounds
Unless these changes remain synchronized across regions, symmetry disappears.
Failover plans still reference symmetrical architecture. Reality no longer reflects it.
Failover as a Behavioral Event
Failover is not simply a routing decision.
It is a behavioral shift across the entire architecture.
Traffic patterns change instantly.
Dependencies experience different load conditions.
Queues process new volumes.
Caching behavior alters.
Understanding failover readiness therefore requires more than infrastructure checks.
Teams must see how services interact across regions.
They must understand how dependencies propagate traffic and where hidden single-region assumptions remain.
Why Visibility Matters
When cross-region dependencies are visible, architects can evaluate resilience realistically.
They can identify:
Services that depend on region-specific infrastructure
Configuration drift between regions
Hidden dependencies that block true failover
Traffic propagation paths during failover scenarios
This visibility transforms resilience planning from assumption to verification.
Cloudshot provides this visibility through live dependency mapping and cross-region architecture context.
Instead of relying solely on diagrams, teams see how systems actually behave across regions.
Resilience Beyond Assumptions
Multi-region design remains one of the most powerful tools for cloud reliability.
But resilience requires more than duplicate infrastructure.
It requires confidence that both regions behave the same way when traffic shifts.
When architects understand dependencies and configuration drift across regions, failover stops being a hopeful plan.
It becomes a verified capability.