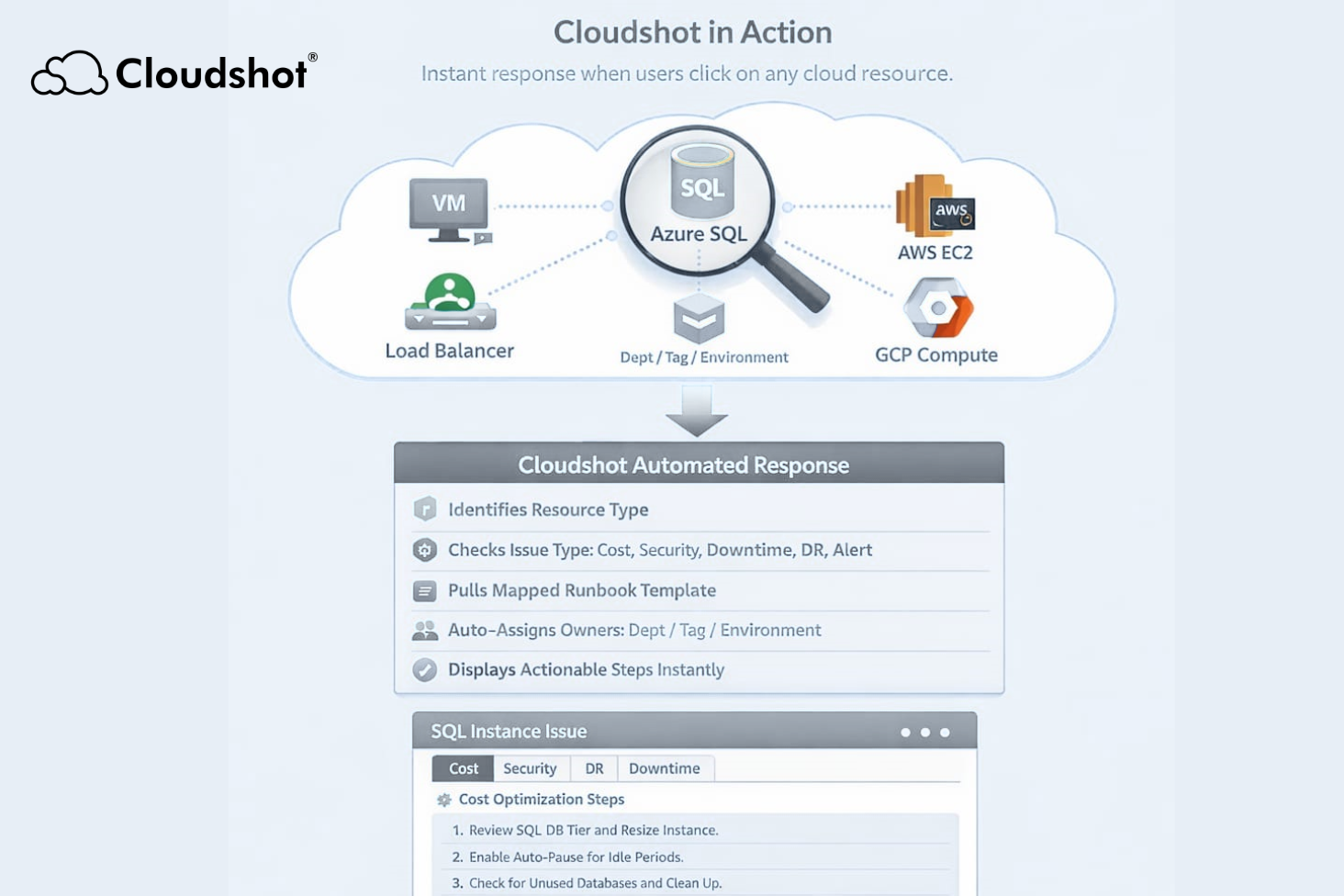
Most incident response failures are not caused by missing documentation.
They happen because the documentation no longer reflects reality.
Modern cloud systems change constantly. Services are added. Dependencies shift. Ownership rotates. Yet most runbooks remain static. They describe how the system used to look, not how it behaves today.
When an incident hits, teams feel this gap immediately.
Why Traditional Runbooks Break Under Pressure
Runbooks are written with good intent. They capture best practices. They document lessons learned. They standardize response.
The problem is not effort.
The problem is context.
During an incident, teams open a runbook and quickly realize:
the service boundaries have changed
the dependencies listed are incomplete
the owners referenced are no longer accurate
Engineers start translating steps into the current topology in their heads. They jump between dashboards to confirm what still applies. Valuable minutes are spent figuring out where the runbook fits, instead of executing it.
This is how runbooks turn into background reading instead of operational tools.
Static Documents Versus Live Systems
Cloud incidents are topology problems.
They unfold across connected services, not isolated components. A failure in one node propagates through dependencies that may not be obvious from logs or alerts alone.
Static runbooks cannot keep up with this reality. They assume a fixed system shape. Modern cloud environments do not stay fixed long enough for that assumption to hold.
Response becomes improvisational.
Teams rely on experience and memory.
Coordination slows. MTTR stretches.
What Topology-Aware Playbooks Change
Topology-aware incident playbooks start from a different premise.
Instead of asking engineers to find the right runbook, the system identifies it for them.
Response begins with the live architecture map.
When an engineer opens the affected node, the playbook adapts automatically. Only the steps relevant to that node and its current dependencies appear. Ownership reflects the present state of the organization, not last quarter's org chart.
This shifts incident response from document navigation to situational awareness.
Context Replaces Guesswork
When runbooks follow the map, several things change at once.
Teams no longer debate which playbook applies.
They no longer ask who owns what.
They no longer translate diagrams into actions under stress.
Instead, they see:
which dependencies are involved
which teams are responsible right now
which steps matter for this topology
Execution becomes faster because context is already aligned.
How Cloudshot Enables Topology-Aware Playbooks
Cloudshot connects incident response directly to live architecture context.
Playbooks are not separate artifacts. They are attached to the system itself.
As infrastructure changes, the playbooks stay relevant because they derive their scope from the topology. When ownership changes, the response path updates automatically. When dependencies shift, the steps adjust.
This does not remove human judgment.
It supports it.
Engineers spend less time orienting themselves and more time fixing the problem.
Why This Matters for Prevention, Not Just Response
The value of topology-aware playbooks is not limited to faster recovery.
They also reveal patterns. Teams see which paths fail repeatedly. They notice where dependencies amplify risk. Over time, incident response informs system design instead of merely reacting to it.
Runbooks stop being static instructions.
They become living operational knowledge.
That is how teams move from firefighting to prevention.